Oracle GoldenGate Veridata 23c – Silent Installation Oracle GoldenGate Veridata 23c Oracle GoldenGate Veridata 23c – Silent InstallationOracle GoldenGate Veridata is an high speed data comparison and repair solution. The new Oracle…VeeraMarch 4, 2025
Oracle GoldenGate Veridata 23c – How to apply patch? Oracle GoldenGate Veridata 23c Oracle GoldenGate Veridata 23c – How to apply patch?In this article, we will be seeing on how to apply the newly released Oracle…VeeraMarch 1, 2025
Oracle GoldenGate Veridata 23c Basic Performance Tuning Oracle GoldenGate Veridata 23c Oracle GoldenGate Veridata 23c Basic Performance TuningTuning Oracle GoldenGate Veridata is essential for several reasons, particularly when working with large datasets…VeeraDecember 25, 2024
Oracle GoldenGate Veridata 23c – SCN based Comparison Oracle GoldenGate Veridata 23c Oracle GoldenGate Veridata 23c – SCN based ComparisonOracle GoldenGate Veridata is more flexible allowing the users to choose what data must be…VeeraDecember 19, 2024
Oracle GoldenGate Veridata 23c Installation Oracle GoldenGate Veridata 23c Oracle GoldenGate Veridata 23c InstallationOracle GoldenGate Veridata 23c has been released recently and is available on-premises. The new Oracle…VeeraDecember 16, 2024
Oracle GoldenGate 23ai Microservices – Installation Oracle GoldenGate 23ai Oracle GoldenGate 23ai Microservices – InstallationOracle GoldenGate Microservices Architecture has been introduced in Oracle GoldenGate version 12.3. On each new…VeeraMay 12, 2024
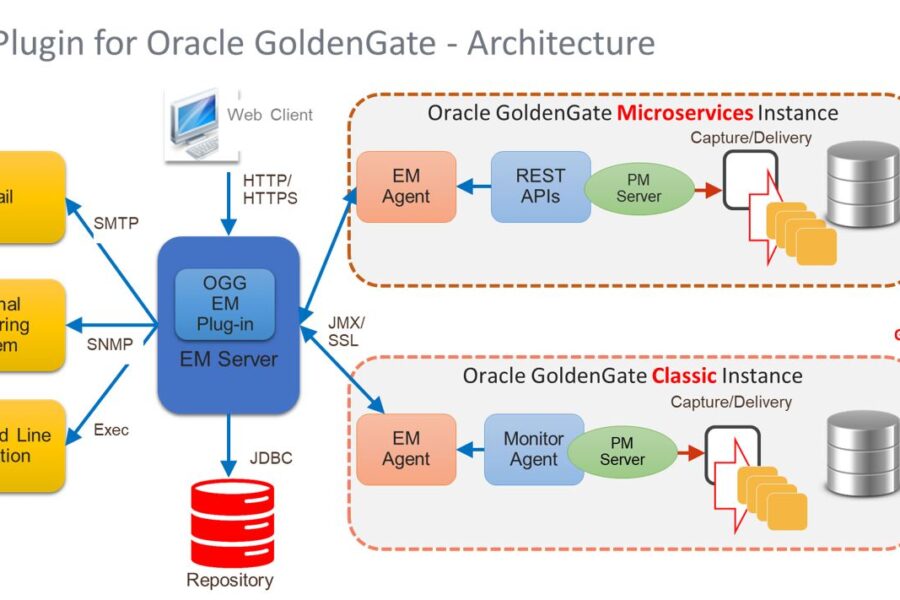
What is Enterprise Manager Plugin for Oracle GoldenGate? EM Plugin for GoldenGate What is Enterprise Manager Plugin for Oracle GoldenGate?The EM Plugin for GoldenGate offers several use cases that help streamline the management and…VeeraApril 28, 2024
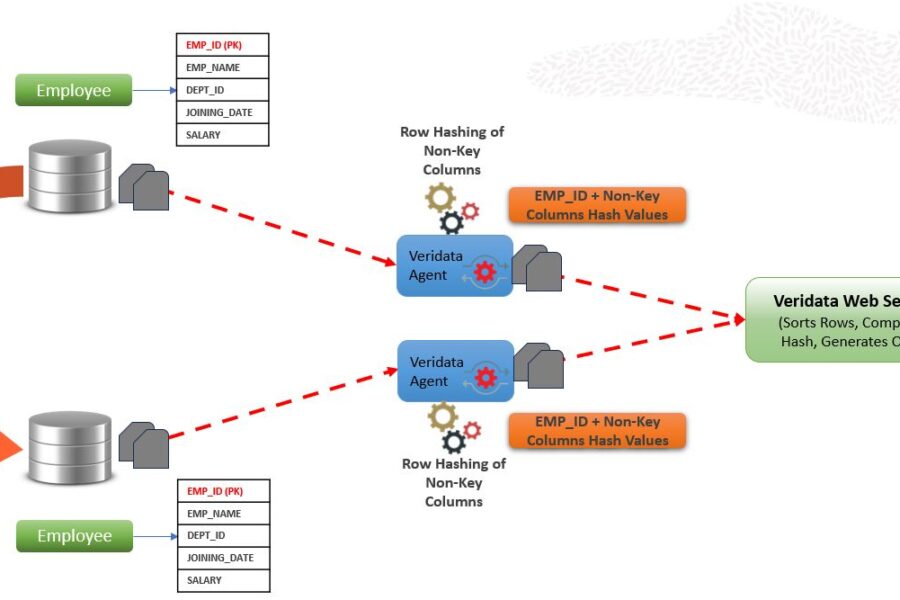
Oracle GoldenGate Veridata – How it works? Oracle GoldenGate Veridata Oracle GoldenGate Veridata – How it works?My previous post was about the Automatic Repair Feature in Oracle GoldenGate Veridata. Hope it…VeeraMarch 17, 2024
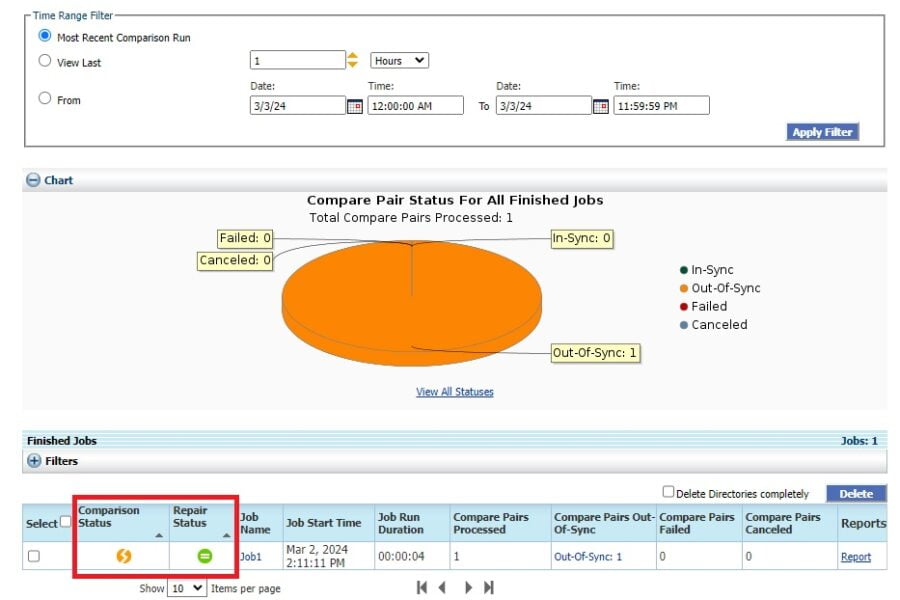
Oracle GoldenGate Veridata – Automatic Repair Feature Oracle GoldenGate Veridata Oracle GoldenGate Veridata – Automatic Repair FeatureAs you know, Oracle GoldenGate Veridata serves as more than just a rapid data comparison…VeeraMarch 3, 2024
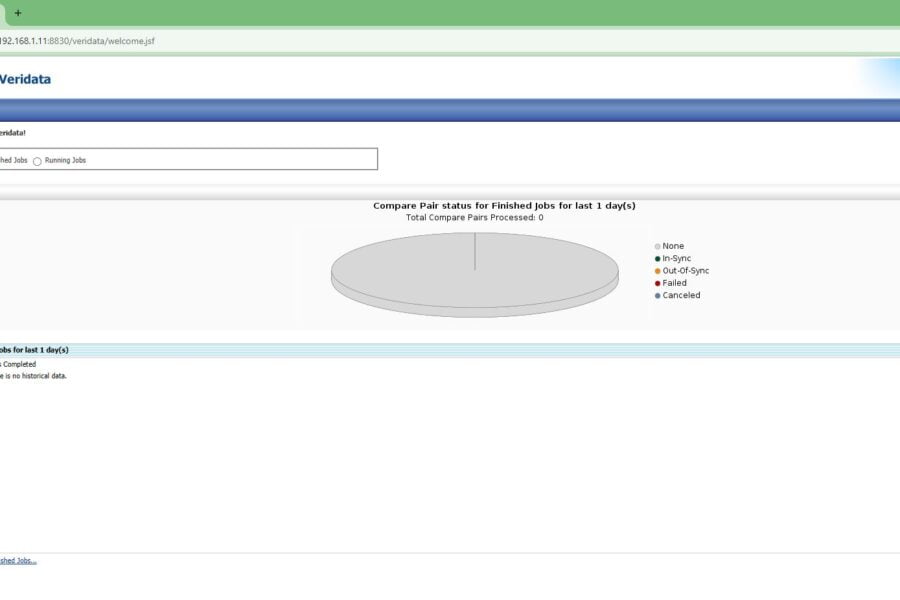
Oracle GoldenGate Veridata – Comparing data between Tables Oracle GoldenGate Veridata Oracle GoldenGate Veridata – Comparing data between TablesOracle GoldenGate Veridata is a high-speed, data-comparison and repair solution that identifies, reports on, and…VeeraJanuary 29, 2024








 Total Users : 1862457
Total Users : 1862457
Recent Comments